| BUSCADOR |
|---|
| INDICE |
|---|
| INDICE PÁGINA ACTUAL |
|---|
Tabla de Contenidos
| BUSCADOR |
|---|
| INDICE |
|---|
| INDICE PÁGINA ACTUAL |
|---|
Para la conexión de servidores en cascada (no necesariamente en estrella, ya que un mismo servidor puede ser cliente y servidor y no estar necesariamente al extremo de la cadena), es necesario efectuar configuraciones diferentes.
Aquí, vamos a explicar qué cosas se pueden hacer con esta configuración, qué cosas no se pueden hacer y cuáles están aún en proyección pero aún no pueden usarse.
| REQUISITOS |
|---|
| La versión de servidor tiene que ser igual o superior a la 3.10.269.842. |
| En cada máquina servidora se instalará solamente el servidor de réplica. El cliente está incorporado dentro del propio servicio. |
| Los requisitos de hardware son los mismos que para un servidor normal. |
| Los clientes no pueden “desplazarse” entre servidores, es decir, un cliente de réplica se registra en uno y solo un servidor de la cadena y replica siempre contra ese servidor. |
| Un mismo cliente con una licencia no puede replicar más que contra el servidor en que se ha registrado. |
En las tablas y campos tenemos los siguientes requisitos:
| En el nodo central se tienen que tener las tablas y campos para replicar por lotes con la versión 2 ó superior. |
| En los nodos que operan como clientes se tiene que soportar la réplica por lotes con la versión 2 ó superior y además: -La tabla master_replica_iqueue tiene que tener los campos de cliente: (STATUS, IDSERVER, DMIDPR y PMAP). -La tabla master_replica_queue tiene que tener el campo CLNTDISABLED (numérico entero). |
Para que no haya problemas, lo mejor sería poner el iqueue de cliente en todas las bases de datos y crear el campo CLNTDISABLED en la cola para todas las bases de datos, lo que permitiría escalar los servidores en cualquier momento.
Las bases de datos se tienen que poner a monitorear en el replicator.ini, algo que doy por sentado, dado que es obligatorio el iqueue, por lo que se necesitará monitorear la base de datos para que el servidor funcione.
Instalar los servidores en cada una de las máquinas.
Se puede instalar una misma licencia de servidor en todas las máquinas de la cadena.
Para cada uno de los servidores de la cadena es necesario poner una licencia de base de datos diferente, ya que será la forma que tengan los diferentes nodos de la cadena de identificarse como clientes en cada uno de los niveles superiores.
En el nodo que será central, se tiene que registrar una licencia para cada uno de los nodos que están conectados directamente a él.
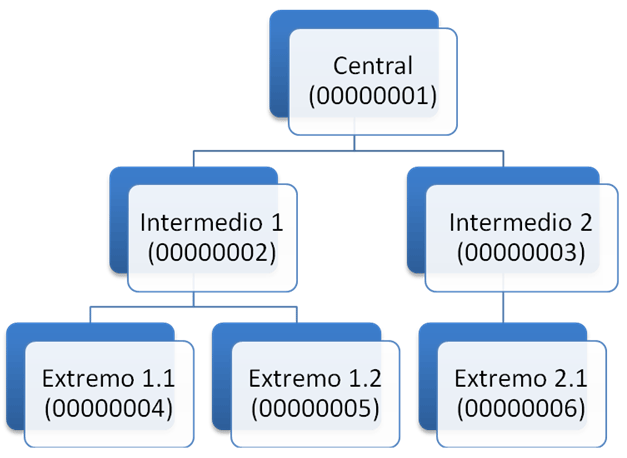
En la Figura 1 se muestra una jerarquía posible con licencias de bases de datos de ejemplo. Así el nodo central será la licencia 00000001 y las licencias 4, 5 y 6 son extremos, las licencias 2 y 3 son nodos intermedios.
Todos los nodos pueden tener clientes de réplica conectados, pero para esos casos no hay nada especial que configurar, por tanto, no vamos a preocuparnos por eso.
Para conectar un nodo servidor con sus nodos esclavos, es necesario crear licencias a los esclavos. En nuestro caso, tenemos que crear una licencia para cada nodo intermedio en el nodo central.
En el nodo intermedio 1 tenemos que crear una licencia para cada nodo extremo (4 y 5) y en el nodo intermedio 2 tenemos que crear una licencia para el nodo extremo 6.
Estas licencias se generan usando el xnetsetup o usando el xonemanager, ya que se trata de clientes normales a efectos de réplica.
Para identificarlas de otros posibles clientes se pueden usar números de MID que muestren diferencias evidentes:
(i.e. MID 1000 para el intermedio 1 y MID 1001 para el intermedio 2, etc. Esto, sin embargo, no es obligatorio, cualquier número de MID puede usarse para identificar un nodo esclavo)
En nuestro caso, vamos a crear dos clientes en el nodo central y vamos a llamarlos 00000001F512345678000101 y 00000001F512345678000201 con los MID 1 y 2 respectivamente.
A continuación, enlazamos los nodos intermedios 1 y 2 con el nodo central, como se muestra en la Figura 2.
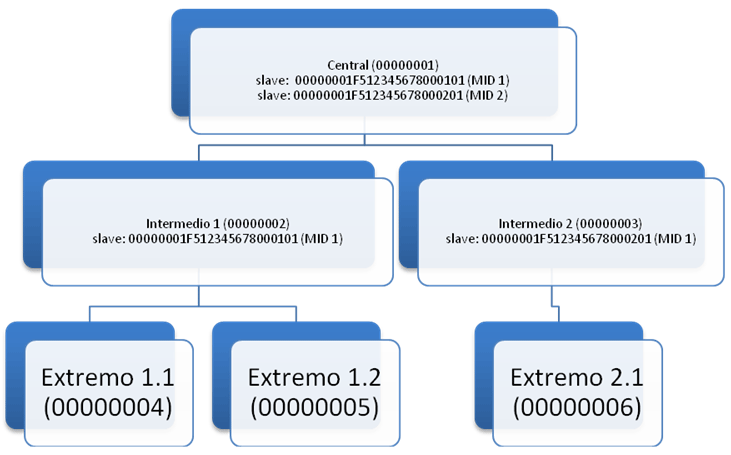
Como puede verse, en el servidor intermedio se ha creado una línea en el slave con el mismo SERIAL que tiene este nodo en el servidor central.
A este MID se le puede poner el número que se quiera, porque realmente ningún cliente en este nodo replicará con ese MID.
En el nodo intermedio 2 ocurre exactamente lo mismo.
En ambos nodos se ha usado el MID 1 como MID de enlace.
Ahora, hay que crear en el nodo intermedio 1 los dos clientes de enlace con sus extremos y en el intermedio 2 el cliente de enlace con el único extremo que tiene.
En la Figura 3 se muestra este trabajo ya realizado.
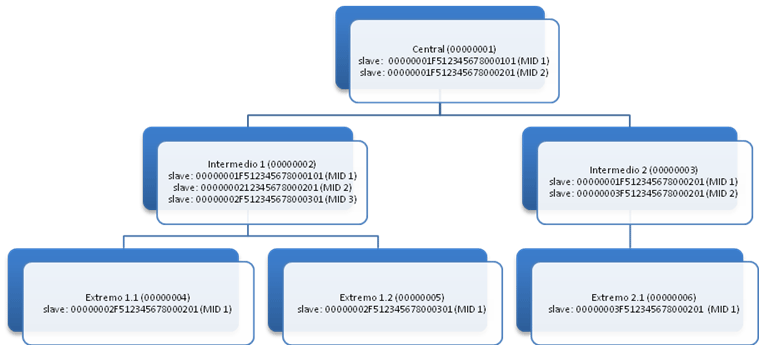
Ahora están todos los nodos enlazados en lo que a licencias se refiere.
Es necesario hacer las siguientes observaciones:
Ahora hay que configurar los nodos que funcionan como cliente (los intermedios y extremos) para conectarse con sus nodos superiores.
Para esto hay que tocar las líneas de slave que se han insertado con número de licencia de enlace.
Los cambios que hay que introducir son los siguientes:
| Campo DIRIP: Poner la dirección del nodo superior (dir[:puerto]). |
| Campo ACTION: Poner la palabra “link”. |
A continuación ponemos los datos de los enlaces tal como quedarían en todos los nodos enlazados, partiendo de una lista de direcciones IP como se indica en la tabla 1:
| NODO | DIRECCIÓN IP |
|---|---|
| Nodo Central | 192.168.1.1 |
| Nodo Intermedio 1 | 192.168.2.1 |
| Nodo Intermedio 2 | 192.168.3.1 |
| Nodo Extemo 1.1 | 192.168.4.1 |
| Nodo Extremo 1.2 | 192.168.5.1 |
| Nodo Extremo 2.1 | 192.168.6.1 |
TABLA 1
Valores de configuración
| NODO | DIRECCIÓN IP | ACTION | SERIAL |
|---|---|---|---|
| Nodo Intermedio 1 | 192.168.1.1 | link | 00000001F512345678000101 |
| Nodo Intermedio 2 | 192.168.1.1 | link | 00000001F512345678000201 |
| Nodo Extremo 1.1 | 192.168.2.1 | link | 00000002F512345678000201 |
| Nodo Extremo 1.2 | 192.168.2.1 | link | 00000002F512345678000301 |
| Nodo Extremo 2.1 | 192.168.3.1 | link | 00000003F512345678000201 |
Ya están configurados los servidores para replicar en cascada.
A partir de este momento, en cada uno de los servidores se pueden registrar nuevos clientes de réplica como se ha hecho siempre y las operaciones se propagarán entre todos los servidores que terminarán teniendo todos los datos equivalentes.
El cliente de réplica incorporado tiene parámetros similares a los clientes independientes, que se configuran en el fichero replicator.ini de la misma forma que en el caso de los clientes móviles actuales (license.ini).
La sección dentro de este fichero es la misma en la que se almacenan los settings de la base de datos, de forma que cada base de datos puede mantener su propia configuración de cliente enlazado.
| Las claves usadas son las siguientes |
|---|
| Interval: Tipo de intervalo (0: milisegundos, 1: segundos, 2: minutos, 3: horas). |
| Timeout: Cantidad de tiempo en el intervalo anteriormente descrito. |
El resto de los valores que pueden ir en el fichero INI son los de siempre en la versión Win32 pero en este caso no los ponemos. Si alguien los necesita, puede solicitarlos.
Cuando un cliente de réplica normal (bien sea un terminal o una interfaz de integración) hace llegar operaciones vía réplica a un nodo que funciona como servidor y cliente, este recibe las operaciones de la misma forma que las ha recibido siempre.
Una vez que estas operaciones se han ejecutado y están en la cola de réplica, el módulo cliente detecta que tiene operaciones que enviar y se conecta con el nodo superior para enviárselas.
Estas operaciones llegarán al nodo superior con el MID que tenga este nodo en su lista de clientes, sea cual sea el MID original que las generó, así que una vez que las operaciones van subiendo de nivel pierden la referencia de quién es el que las ha generado.
Cuando el nodo termina de subir las operaciones, empieza a bajar las que haya disponibles y las inserta en el iqueue como si fuera un cliente de réplica normal.
El trabajo de ejecución de iqueue del servidor identificará estas operaciones como procedentes de un trabajo de cliente porque conoce el MID de enlace, así que las ejecutará siguiendo las reglas necesarias (primero las que tengan estado DMID y después las que tengan estado normal, etc.) Por lo demás la ejecución de operaciones es similar tanto para las procedentes de clientes como las procedentes de servidores superiores en cuanto a resolución de mapeos, conflictos, etc.
Si se quiere que el nodo central opere a modo de recolector de datos y nunca propague datos hacia los nodos inferiores, basta con poner los clientes de enlace como condicionales y dejar sus selected vacías. De esta manera, ninguna operación pasará nunca al squeue para estos clientes y estos nunca tendrán operaciones que bajarse.
Los nodos intermedios se pueden configurar de la misma forma. Con este esquema lo que ocurriría es que tendríamos un servidor central con todos los datos procedentes de todos los clientes de réplica y servidores intermedios con subconjuntos de datos que corresponderían solo a cada uno de los grupos de clientes que atienden.
Esto permite tener un sistema de delegaciones aisladas y sin peligro de que se mezclen los datos en cada una de las delegaciones. En la central se recogerían todos los datos (i.e. pedidos, facturas, etc.) que se hagan en cada delegación.
Si los clientes se configuran sin selectividad, lo que tendríamos serían copias equivalentes de la base de datos central en cada nodo, con lo que tendríamos el caso opuesto: una base de datos central distribuida entre todos los servidores.
Dicho módulo no está implementado en esta versión.
Hasta la fecha hay aspectos conceptuales que aún no tenemos resueltos a nivel de diseño.
De momento, la estructura es la que es: clientes fijos en sus nodos y propagación de datos entre servidores.
Los clientes no pueden cambiar de servidor de forma dinámica.
